Abstract
Discovering meaningful directions in the latent space of GANs to manipulate semantic attributes typically requires large amounts of labeled data. Recent work aims to overcome this limitation by leveraging the power of Contrastive Language-Image Pre-training (CLIP), a joint text-image model. While promising, these methods require several hours of preprocessing or training to achieve the desired manipulations. In this paper, we present StyleMC, a fast and efficient method for text-driven image generation and manipulation. StyleMC uses a CLIP-based loss and an identity loss to manipulate images via a single text prompt without significantly affecting other attributes. Unlike prior work, StyleMC requires only a few seconds of training per text prompt to find stable global directions, does not require prompt engineering and can be used with any pre-trained StyleGAN2 model. We demonstrate the effectiveness of our method and compare it to state-of-the-art methods.

StyleMC Framework
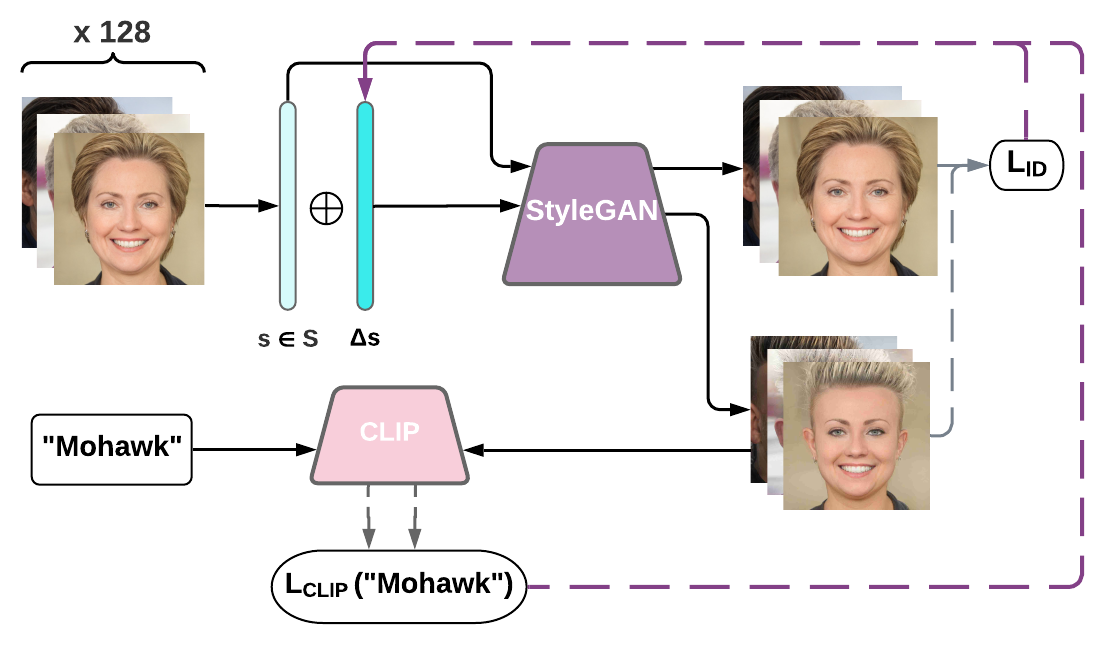
The architecture of StyleMC (using the text prompt "Mohawk" as an example). The latent code s and ∆s+s are passed through the generator. The global manipulation direction ∆s corresponding to the text promptis optimized by minimizing CLIP loss and identity loss.
- Fast Manipulation: We propose a fast text-guided image generation and manipulation method that finds multiple style channels which control the desired attributes in 5s per text.
- Low resolution layers: Unlike previous work, our method finds directions using only layers up to 256×256 resolution within StyleGAN2, providing a significant speedup. We then use the found directions to apply manipulations and generate images at high resolutions such as 1024×1024.
- Small batch of images: Our method uses only 128 randomly generated images to find stable and global manipulation directions regardless of the given text prompt.
 A variety of manipulations on SyleGAN2 FFHQ model. Rows 1-4 shows inverted real images and Rows 5-8 showsrandomly generated images.The text prompt used for the manipulation is above each column.
A variety of manipulations on SyleGAN2 FFHQ model. Rows 1-4 shows inverted real images and Rows 5-8 showsrandomly generated images.The text prompt used for the manipulation is above each column.











