Abstract
Recent work such as StyleCLIP aims to harness the power of CLIP embeddings for controlled manipulations. Although these models are capable of manipulating images based on a text prompt, the success of the manipulation often depends on careful selection of the appropriate text for the desired manipulation. This limitation makes it particularly difficult to perform text-based manipulations in domains where the user lacks expertise, such as fashion. To address this problem, we propose a method for automatically determining the most successful and relevant text-based edits using a pre-trained StyleGAN model. Our approach consists of a novel mechanism that uses CLIP to guide beam-search decoding, and a ranking method that identifies the most relevant and successful edits based on a list of keywords. We also demonstrate the capabilities of our framework in several domains, including fashion.

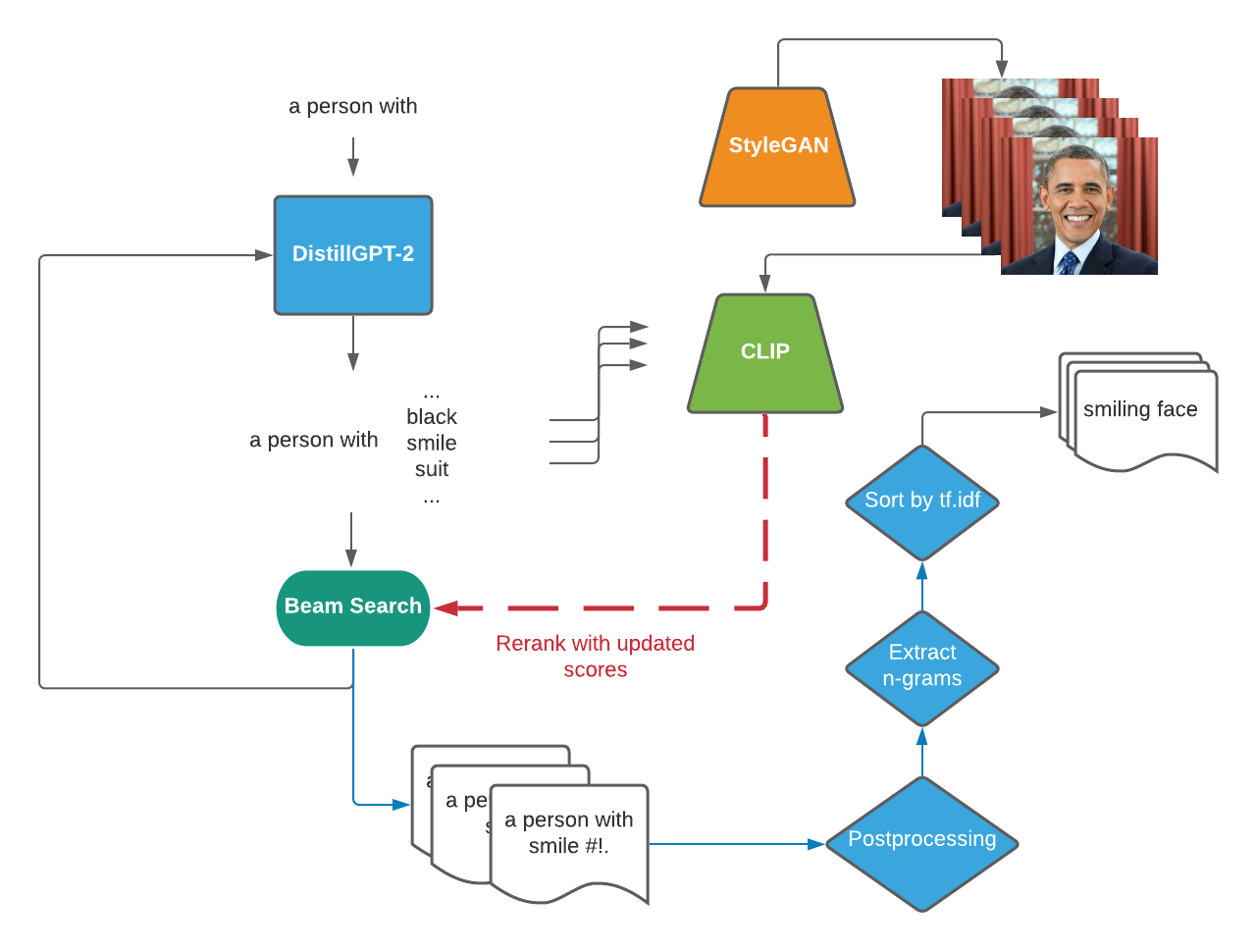
Framework of RankInStyle
- For finding best channels to perform manipulations, we rank channels by the value of \( \mathcal{V}_{R} \mathcal{V}_{E} \)
- We compute the relevance as the similarity between generated images and keywords in the CLIP embedding space. \begin{equation} \begin{split} \mathcal{V}_{R} = \mathcal{S}_{CLIP}(G(s),t) \end{split} \end{equation}
- Since the relevance is not enough to assess if a manipulation is successful, we measure editability, the increase in the relevance after the manipulations. \begin{equation} \begin{split} \mathcal{V}_{E} = \frac{\mathcal{S}_{\text{CLIP}}(G(s+\alpha), t) - \mathcal{S}_{\text{CLIP}}(G(s), t)}{ L_2(\text{CLIP}(G(s+\alpha)) - \text{CLIP}(G(s)))} \end{split} \end{equation}
- We rerank beams using the CLIP similarity between a generated image and candidate text.

 Shows the manipulations that our method provides for FFHQ
Shows the manipulations that our method provides for FFHQ
 Shows the manipulations that our method provides for AFHQ cats
Shows the manipulations that our method provides for AFHQ cats



 Results for human evaluation experiment with mean and std values for RankInStyle, SeFa and GANSpace
Results for human evaluation experiment with mean and std values for RankInStyle, SeFa and GANSpace
