
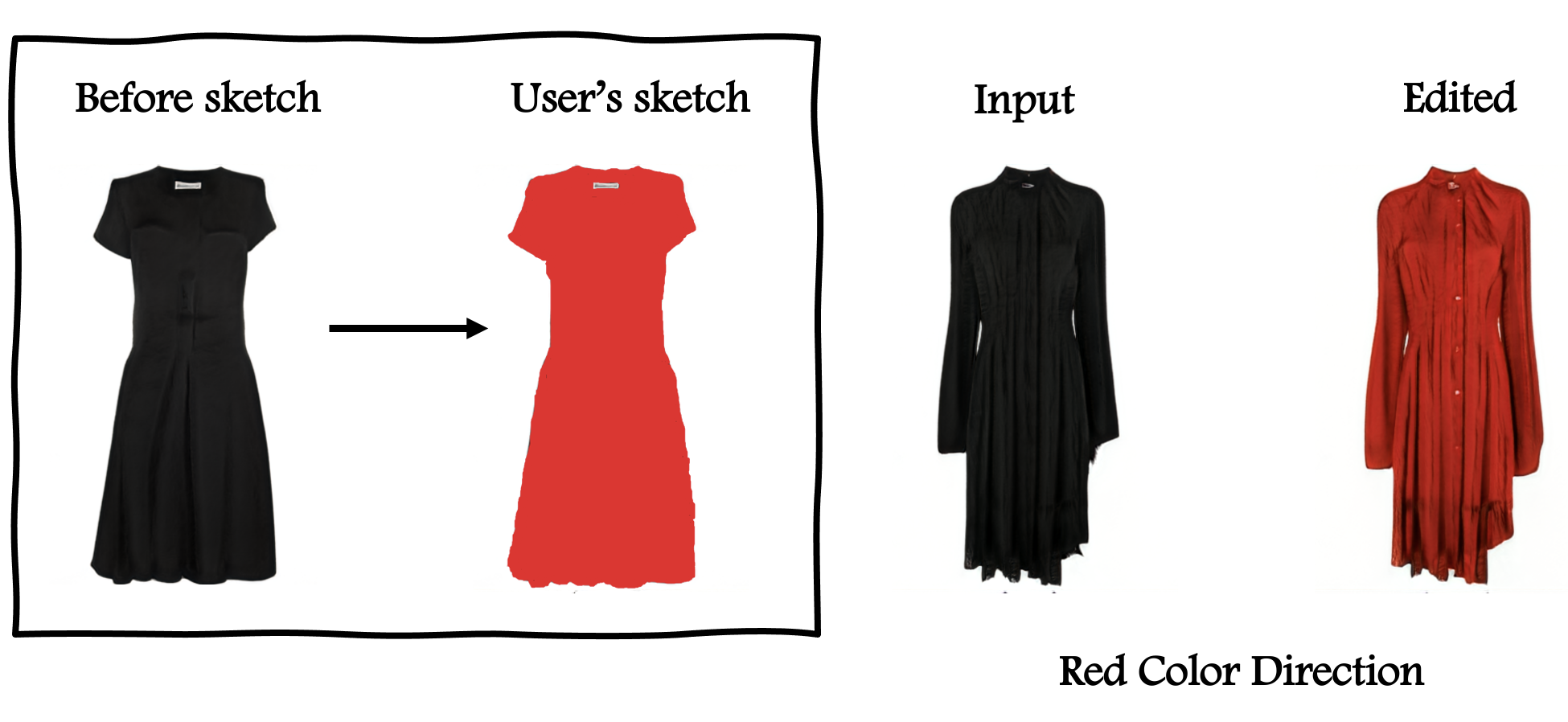
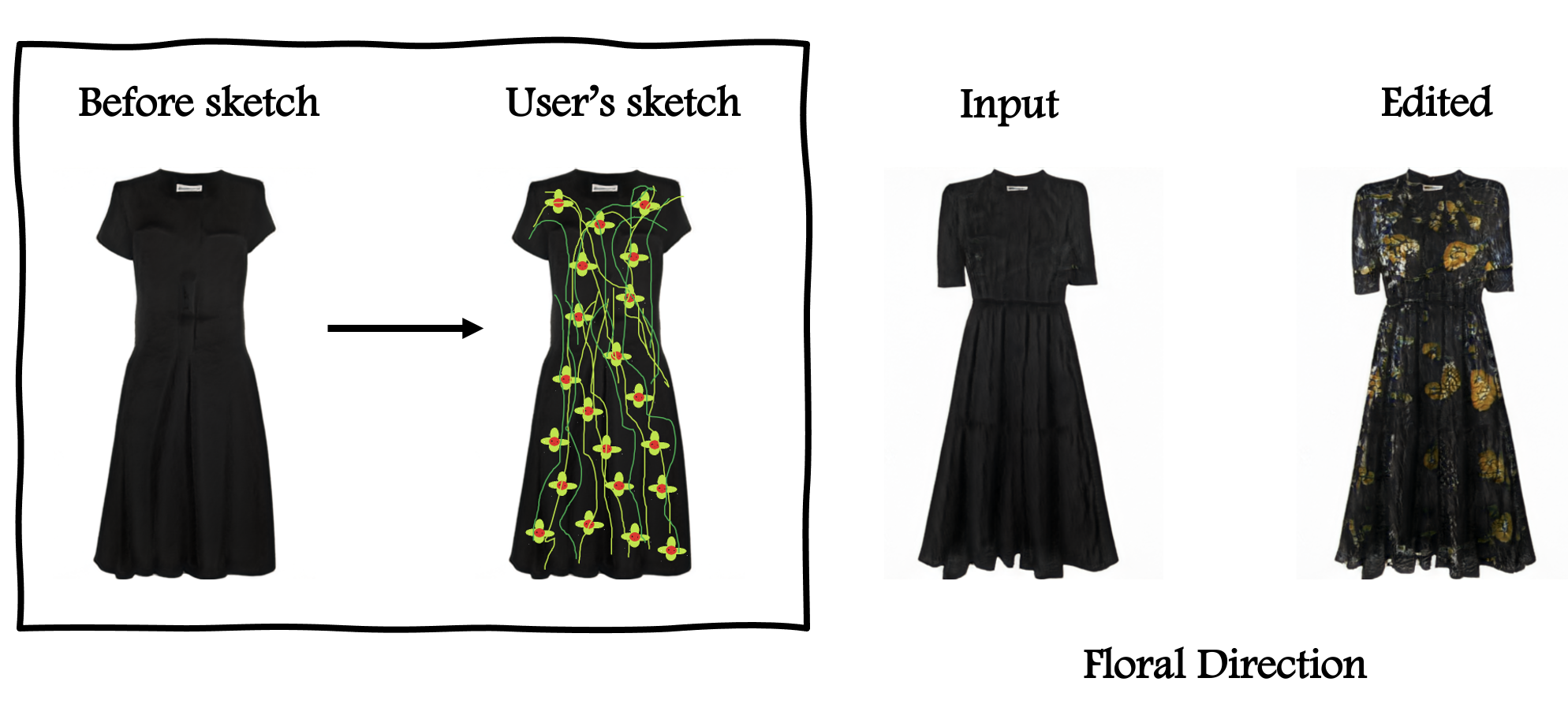
Interpretable directions discovered using our method in the FFHQ dataset. The user drawings on the left are used to manipulate the images in the center to the images on the right.
The search for interpretable directions in latent spaces of pre-trained Generative Adversarial Networks (GANs) has become a topic of interest. These directions can be utilized to perform semantic manipulations on the GAN generated images. The discovery of such directions is performed either in a supervised way, which requires manual annotation or pre-trained classifiers, or in an unsupervised way, which requires the user to interpret what these directions represent.
Our goal in this work is to find meaningful latent space directions that can be used to manipulate images in a one-shot manner where the user provides a simple drawing (such as drawing a beard or painting a red lipstick) using basic image editing tools. Our method then finds a direction that can be applied to any latent vector to perform the desired edit. We demonstrate that our method is able to find several distinct and fine-grained directions in a variety of datasets.
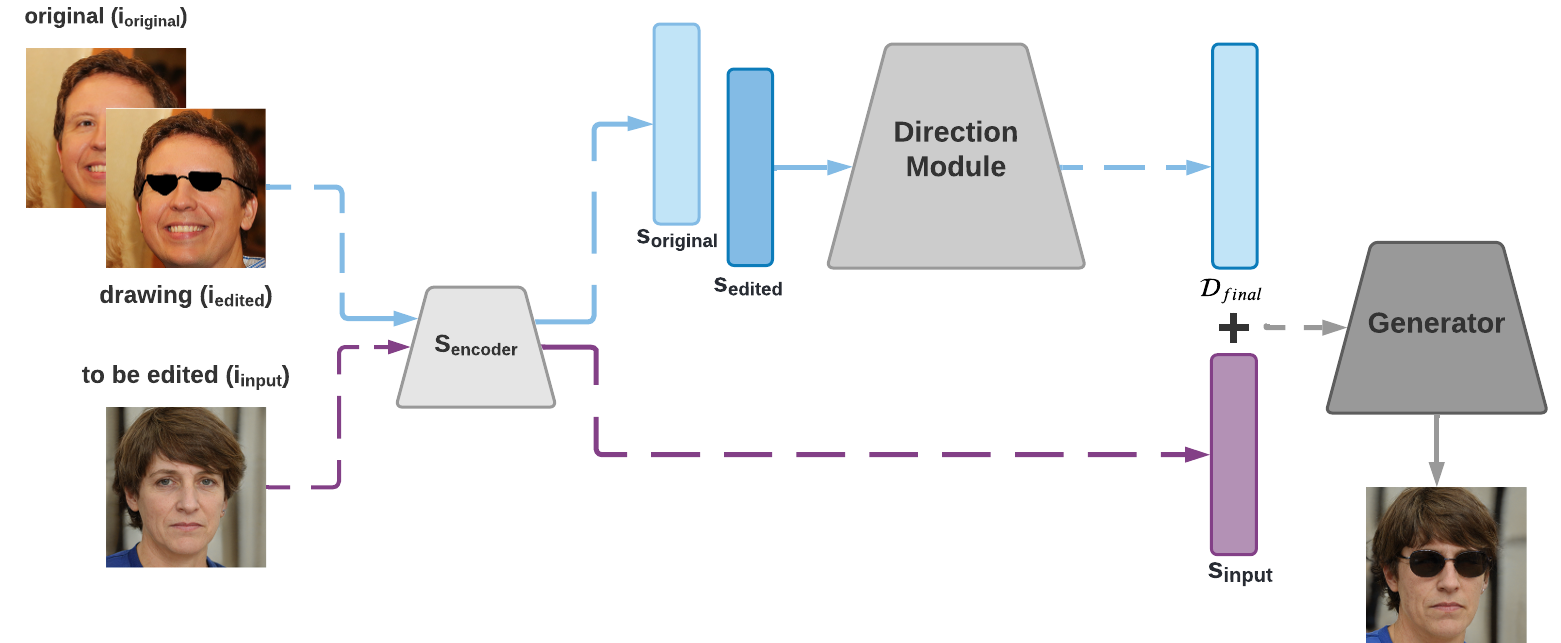 Our method takes an original and edited image and identifies a direction using the Direction Module.
The identified direction can then be used for manipulating new images.
Our method takes an original and edited image and identifies a direction using the Direction Module.
The identified direction can then be used for manipulating new images.

As can be seen in above figure, the final direction preserves the features of the original image better than the basic direction while successfully manipulating the target attribute. This improvement can be observed for the long hair and white hair directions. The basic direction manipulates the image towards the desired attribute but also changes the gender of the original image in the long hair direction and the identity of the input in the white hair direction. In addition, basic direction may lead to incorrect manipulations in the drawing region. For instance, the basic direction produces a hat instead of afro hair. Increasing the number of images in the direction module further improves the quality of the direction, as can be seen from the last column.
 Various edits made to human faces using our method. The manipulations are in the top
row with the corresponding labels. The rows represent randomly generated human faces.
The last row shows the manipulations on a real image.
Various edits made to human faces using our method. The manipulations are in the top
row with the corresponding labels. The rows represent randomly generated human faces.
The last row shows the manipulations on a real image.


@InProceedings{Doner_2022_CVPR,
author = {Doner, Berkay and Balcioglu, Elif Sema and Barin, Merve Rabia and Kocasari, Umut and Tiftikci, Mert and Yanardag, Pinar},
title = {PaintInStyle: One-Shot Discovery of Interpretable Directions by Painting},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
month = {June},
year = {2022},
pages = {2288-2293}
}This publication has been produced benefiting from the 2232 International Fellowship for Outstanding Researchers Program of TUBITAK (Project No:118c321). We also acknowledge the support of NVIDIA Corporation through the donation of the TITAN X GPU and GCP research credits from Google.