
Methodology
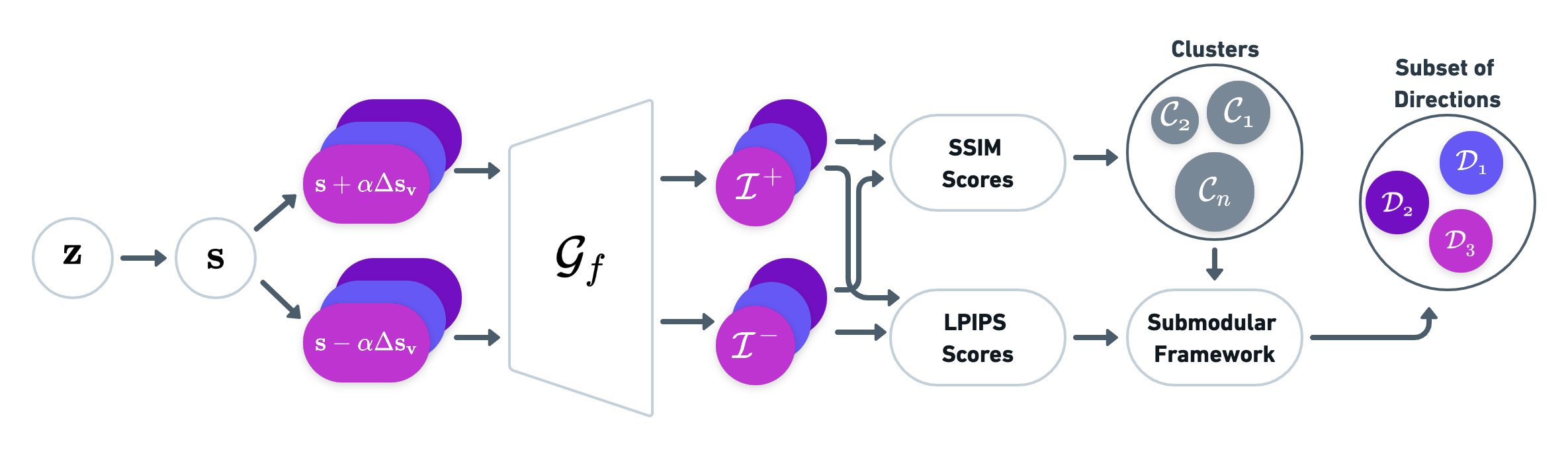
Let $\mathcal{V}$ represent the set of style channels in the stylespace. Then, we are interested in selecting a small subset of channels $\mathcal{P} \subseteq \mathcal{V}$ that are most representative and diverse. To measure the overall coverage or fidelity of the channels in $\mathcal{P}$, we can define a set function as follows, \begin{equation} \mathcal{F}_{coverage}(\mathcal{P}) = \sum_{v_i \in \mathcal{V}, v_j \in \mathcal{P}} \mathcal{F}_{\text{sim}}(v_i, v_j) \label{eq:coverage} \end{equation} which simply computes the similarity between the summary set $\mathcal{P}$ and the ground set $\mathcal{V}$. In other words, it measures some form of coverage of $\mathcal{V}$ by $\mathcal{P}$. $\mathcal{F}_{\text{sim}}$ measures the similarity between two channels using SSIM metric. However, this function does not take diversity into account, since the value of the covering a particular type of edit (such as hair or background) never diminishes. A common approach is to apply a diversity regularization to our objective function [1], where we aim to reward items selected from different groups of directions such that: \begin{equation} \mathcal{F}_{diversity}(\mathcal{P}) = \log \left( 1 + \sum_{k=1}^K \left( \sum_{v_i \in \mathcal{C}_k \cap \mathcal{P}} \mathcal{F}_{\text{reward}}({v_i}) \right) \right) \label{eq:diversity} \end{equation} where the ground set $\mathcal{V}$ of style channels is partitioned into $K$ separate clusters. The clusters $\mathcal{C}_k$ are disjoint, where $k=1, \ldots K$ and $\bigcup_k \mathcal{C}_k = \mathcal{V}$. For each style channel $v_i$, we have a reward $\mathcal{F}_{\text{reward}}({v_i}) \geq 0$, which indicates the importance of adding channel $v_i$ to the empty set which is computed using LPIPS metric. Then, the overall objective function we want to solve is a combination of both: \begin{equation} \mathcal{F}(\mathcal{P}) = \mathcal{F}_{coverage}(\mathcal{P}) + \lambda \mathcal{F}_{diversity}(\mathcal{P}) \label{eq:submod_channels} \end{equation} where $\lambda \geq 0$ is the tradeoff coefficient between coverage and diversity. Since we are interested in selecting a small subset, we aim to maximize the following objective function, \begin{equation} \mathcal{P}^* = argmax_{\mathcal{P} \subseteq \mathcal{V}: |\mathcal{P}| \leq n} \mathcal{F}(\mathcal{P}) \label{eq:argmax} \end{equation} subject to a cardinality constraint $n$, which denotes the total number of channels in the set $\mathcal{P}^*$. This objective function combines two aspects in which we are interested: 1) it encourages the selected set to be representative of the stylespace, and 2) it positively rewards diversity. Finding the exact subset that maximizes this equation is intractable. However, it has been shown that maximizing a monotone submodular function under a cardinality constraint can be solved near optimally using a greedy algorithm [2]. In particular, if a function $\mathcal{F}$ is submodular, monotone and takes only non-negative values, then a greedy algorithm approximates the optimal solution of this equation within a factor of $(1 - 1/e) $ [2].
Experiments
Clustering Stylespace Our submodular framework relies on the clusters to encourage diversity. Clusters from the FFHQ, Fashion, AFHQ Cats, LSUN Cars, and Metfaces datasets are shown below. We note that clusters that modify similar regions are grouped together, such as smile, hairstyle, expression in FFHQ, neck type, color, pattern in Fashion, eye color, eye, ear type in AFHQ Cats, roof type, ground, bumper type in LSUN Cars, eyebrow type, hairsyle, expression in Metfaces.

Covering stylespace Figure 6 shows the top 10 channels ranked by our method considering multiple layers. As can be seen from the results, our method selects a variety of channels that modify regions such as background, hair, face, mouth, eye, ear, and clothing. Our method yields more disentangled and diverse directions compared to Ganspace and SeFa. For example, while both Ganspace and SeFa change semantics in the input, such as gender, age, eyeglasses, while also changing other semantics such as background, position, highlight at the same time. In contrast, our method performs disentangled edits by changing one semantic at a time.

Applications
Our framework also opens up possibilities for interesting applications that help users discover new directions.Interactive Editing Users can navigate the stylespace by drawing a region of interest such as hair and retrieving relevant clusters and corresponding channels.

Exploration Platform We also provide a web-based platform called StyleAtlas at https://catlab-team.github.io/styleatlas where users can explore the stylespace in a fine-grained way. This tool allows users to explore the manipulations made by specific channels based on the region and discover style channels of interest.
Conclusion
In this work, we consider the selection of diverse directions in the latent space of StyleGAN2 as a coverage problem. We formulate our framework as a submodular optimization for which we provide an efficient solution. Moreover, we provide a complete guide to the stylespace in which one can explore hundreds of diverse directions formed by style channels using clusters. In our experiments, we have shown that our method can identify a variety of manipulations, and performs diverse and disentangled edits.
Acknowledgements
This publication has been produced benefiting from the 2232 International Fellowship for Outstanding Researchers Program of TUBITAK (Project No:118c321).
References
[1] Lin, H., & Bilmes, J. (2011, June). A class of submodular functions for document summarization. In Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies (pp. 510-520).[2] Nemhauser, G. L., Wolsey, L. A., & Fisher, M. L. (1978). An analysis of approximations for maximizing submodular set functions—I. Mathematical programming, 14(1), 265-294.